Finding a job can be tough regardless of location ... so why not use our skills as data scientists to make things a little easier? This blog post will describe how I was able to pull data from one of the most popular online job boards, and prepare it for future data exploration. This will all be done in hopes of gaining a better picture of what to expect in the LA job market.
A College Student's Quest to Find a Job in Los Angeles
Introduction
Landing a job fresh out of college can be a tough feat, especially for those of us trying to find a job in Los Angeles, California. Born and raised in and around the city, I have always planned on returning to the Los Angeles area after college. However, what I did not consider while drawing up this plan, was the current state of the job market, which lead me to wonder what opportunities are really out there.
Job Outlook for 2024
Position openings for newly-graduated students have on average, been cut in half since 2023 and the average time needed to acquire a job lies around 6 months. Many employers are now also requiring more experience than the average college graduate currently has. This added experience can include problem-solving skills, business communication, and leadership.
Motivation
As a student quickly approaching her graduation date, I have taken a strong interest in determining for myself what jobs in my field are currently available in Los Angeles. For this blog, I have chosen to scrape job data for Data Scientist positions (or similar) from Indeed because it is one of the most popular online job boards throughout the country. In this post, I will explain how I was able to use Indeed’s website to gather valuable job data in Los Angeles, and what steps I took to make the data more usable for future EDA purposes.
Acquiring the Data
Is Using This Data Allowed?
The short answer is yes! Any information that can be attained from Indeed’s web API is allowed to be scraped. After researching the Indeed API, it turns out a lot of work goes into using the API, and creating your own scraper is much easier to do. As long as you are using public job data (no personal info) and have legal uses for the data, there should be no problem scraping what you need.
My Data Collection Toolbox

In Python, I used webdriver from the Selenium package to launch Chrome, which is the browser I am most familiar with using. I additionally used Numpy and Pandas which are also Python libraries to clean my data once it was gathered.
Building a Working Web-Scraper
Step 1. Find the url of the site you would like to scrape
For this blog, I used Indeed, narrowed my job search to within 25 miles of Los Angeles, and got the url shown below. I could then use webdriver.Chrome() to launch Chrome.
url = 'https://www.indeed.com/jobs?q=Data+Science&l=Los+Angeles%2C+CA&vjk=74cadd03cb0dd918'
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.get(url)More information on Selenium’s WebDriver for debugging purposes can be found here.
Step 2. Containers and Pagination
Before collecting specific job data, I had to find in the HTML where the container for all the jobs is located. This way, I can locate within that container, all the individual job elements. This list of all job elements on a page can be used later in my code to iterate through. Below is an example of how I found both of these elements in my code.
container = driver.find_element(By.XPATH,
".//div[contains(@id, 'mosaic-jobResults')]")
all_jobs = container.find_elements(By.XPATH,
".//div[contains(@class, 'job_seen_beacon')]")Guide on .find_element(s)
The variable all_jobs should now be a list containing each job card on the first page.
After looking at all 15 jobs on the first page, I would also like my web-scraper to be able to click to the next page if applicable, and continue gathering information from multiple pages. To do this, I need both a pagination variable and to find the next button. Pagination refers to the navigation bar at the bottom on websites that have multiple pages you can move between.

There should also be HTML code within the pagination HTML tag that represents the next button you can click. We want to locate that, save it as a next button variable, and use next.click() to click to the next page.
pagination = driver.find_element(By.XPATH, ".//nav[contains(@role, 'navigation')]")
... Code To Collect Data on One Page ...
try:
next = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By XPATH, ".//a[contains(@aria-label, 'Next Page')]")))
next.click()
except:
print(f'failed on page {page_num})
breakAt this point, we should have the general navigational tools, and job card information necessary to carry out our data extraction.
Step 3. What information would you like to gather?
For this particular dataset, I was most interested in finding what I could on the following categories:
Title- Job TitleCompany- Company NameCityandStatePay- Salary AmountJob_Description- Job DescriptionWhen_Posted- How long ago was this posted?Rating- Company RatingWork_Environment- Location Type (On-Site, Hybrid, Remote)
Most of this information was readily available on the job postings, but in order to gather this data, I needed to locate where each item would be found in the HTML code.
In the code provided below:
all_jobsrefers to the list of job cards found abovejob.find_elementsearches for the occurence of a given XPATH within a single job posting- Many job cards ordered their
LocationandSalarydetails differently, so the two try/excepts handle these cases
for job in all_jobs:
title = job.find_element(By.XPATH, ".//h2[contains(@class, 'jobTitle')]").text
try:
location = job.find_element(By.XPATH, ".//div[contains(@class, 'company_location')]").text.split("\n")[1]
except:
location = job.find_element(By.XPATH, ".//div[contains(@class, 'company_location')]").text.split("\n")[0]
company = job.find_element(By.XPATH, ".//div[contains(@class, 'company_location')]").text.split("\n")[0]
when_posted= job.find_element(By.XPATH, ".//tr[contains(@class, 'underShelfFooter')]").text.split("\n")[-1].strip("More...")
description = job.find_element(By.XPATH, ".//tr[contains(@class, 'underShelfFooter')]").text.split("\n")[0]
try:
string = job.find_element(By.XPATH, ".//div[contains(@class, 'salary-snippet-container')]").text
listy = string.split()
for element in listy:
if "$" in element:
pay = element
except:
pay = "NaN"
job_titles.append(title)
job_pays.append(pay)
company_names.append(company)
descriptions.append(description)
company_locations.append(location)
posted.append(when_posted)When scraping data from a website, the data can often require some serious cleaning! For example, I really wanted my salary data to be floats, but that would be difficult had I left them as strings with $ and/or , contained in it. It can also be noted that in my initial scrape, I was not able to get any information for my Work_Environment column. This is because the different evironment types were part of the location strings. This means I also had to separate the locations and determine whether or not it had the keywords that could help sort into my three categories: Hybrid, Remote, and On-Site.
After making the necessary improvements to my data, I was able to create the final cleaned dataframe below.
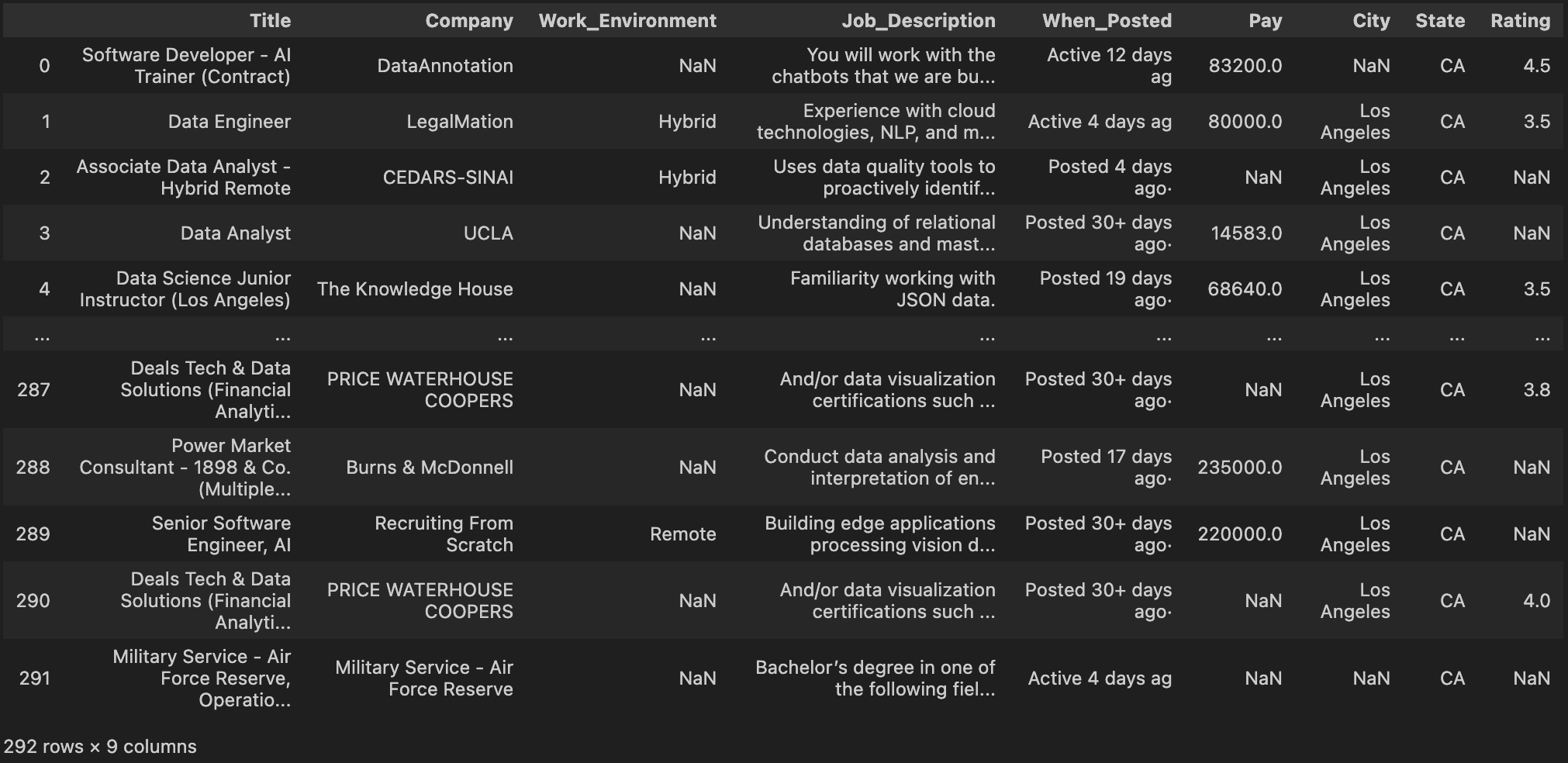
Conclusion
Interested in seeing some EDA conducted on this data?
Now that I have gone through the steps of gathering useful job information from Indeed, in my next post, I can share my findings from conducting some exploratory data analysis. I hope to answer questions such as:
- What jobs have the highest pay?
- How likely am I to work remote versus in person?
- Los Angeles is a big county, which cities have the highest pay?
Stay tuned to see what the data has to say regarding these topics of interest! Please reach out with potential areas for improvement or additional research topics I might want to consider moving forward.